With the advancements in AI technology, companies increasingly seek to explore how artificial intelligence can help solve quality control inspection tasks faster and better.
There are now commercially available standard AI platforms that can solve various tasks such as object detection, anomaly detection, classification, and optical character recognition.
However, there are certain limitations that companies should be aware of when using these standard solutions. In this blog post, we'll explore five common pitfalls to look out for when working with standard AI models for machine vision projects.
Lack of Control over Training Process
One of the biggest drawbacks of using standard AI models is the lack of control over the training process. It is important to choose the right network model or architecture that best suits your problem, especially in industries where errors can have serious consequences.
To ensure the highest precision possible, research different network architectures and choose the model that best fits your specific problem.
Poor Annotation Practices
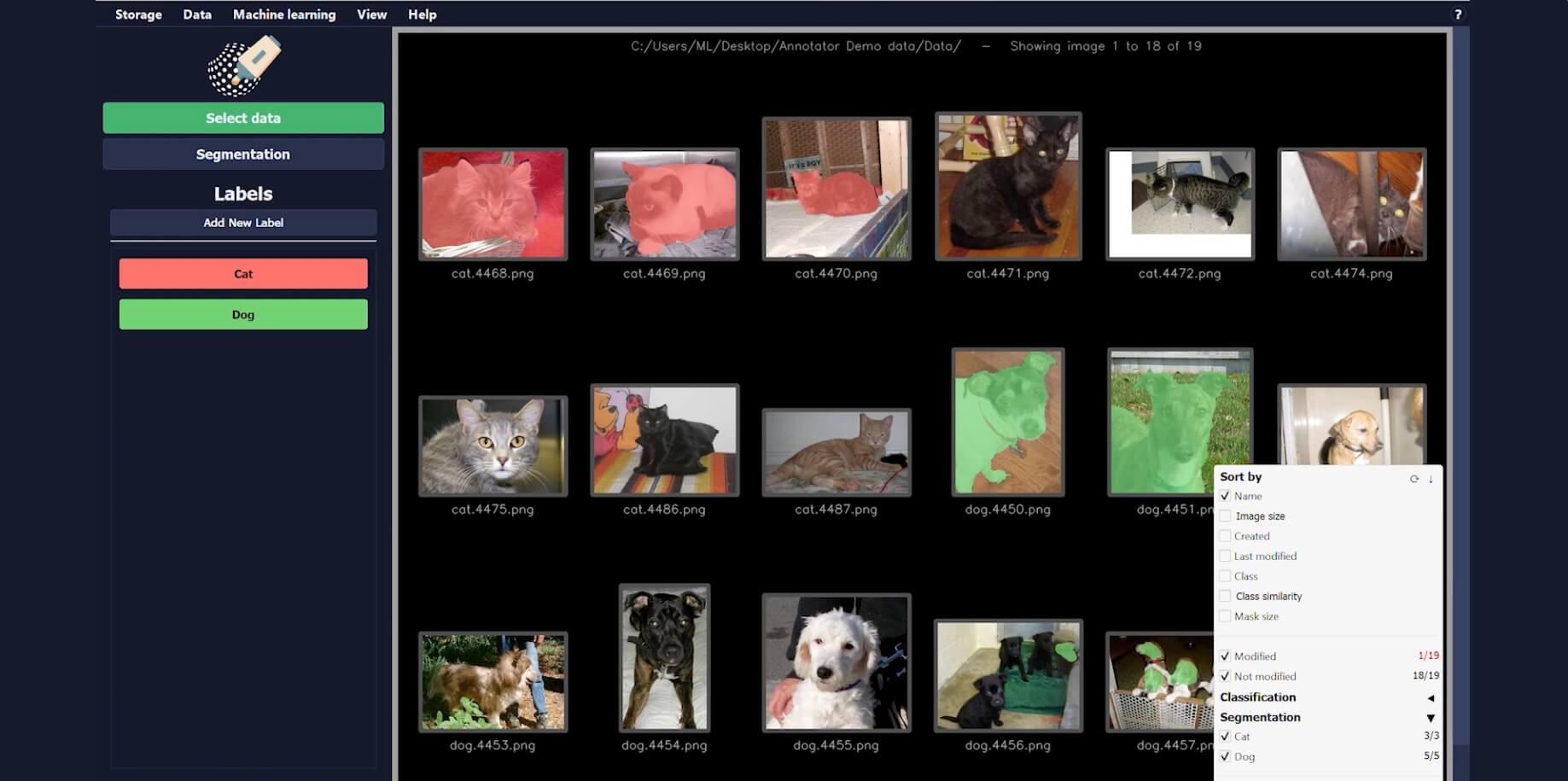
The quality of training data, or annotation, is crucial in determining the performance of an AI model. If the annotated data is inconsistent or inaccurate, it can result in suboptimal performance of the network. For example, if you tell the network that the dog it sees is a cat, it will trust this information completely, leading to confusion and reduced performance.
It is important to be precise and thorough when annotating images. Some AI platforms offer the possibility to take a shortcut and give you suggestions for annotations on the next 100 images based on the annotations done for the first 100.
That is a tempting way of saving time but should be avoided. This way you actually don’t give the network anything new to learn from which will lead to a lack of diversity in the training data.
Improper Class Weighting
Another common mistake is improper class weighting, which occurs when one class error occurs much more frequently than the others. This can result in the network disproportionately training on this one error, skewing its performance and accuracy.
To prevent this, it is important to weigh the classes correctly, ensuring that the network is trained on a balanced distribution of errors.
Validating on Your Training Data
Some standard AI platforms make the mistake of accepting a large pool of data for both training and validation. This can lead to the network not generalizing well to new raw inputs, as the validation and testing data is not independent of the training data.
To ensure that the network is trained correctly, it is important to split the data into separate sets for training, validation, and testing and make sure that the network is exposed to new, unseen data during the validation and testing phase.
Inability to Add New Classes or Errors
Finally, it is not uncommon for companies to encounter new classes or errors that they would like to add to their network after having used it for some time. In some standard AI platforms, adding a new class requires retraining the entire network from scratch, which can be time-consuming and problematic.
Make sure you have the possibility to add a new class to the network without having to retrain it completely, as is often done when building a custom solution.
In conclusion, standard AI platforms can be a great solution for many straightforward machine vision tasks, but it is important to be mindful of the limitations that come with them. By avoiding these common mistakes, companies can ensure that their AI models are accurately and effectively trained to meet their specific needs and requirements.
Read more about AI in machine vision here: